Von Marina Schürmann
Deep Learning als Teilgebiet der künstlichen Intelligenz ist heute in aller Munde. Dies ist nicht verwunderlich, haben entsprechende Verfahren bei der automatischen Verarbeitung von Bild-, Sprach-, und Audiodaten doch massive Fortschritte erzielen können.
Bei tabellarischen Daten hingegen ist der Vorteil von Deep Learning gegenüber herkömmlichen Machine Learning Methoden unklar. In ihrer 2022 erschienen Publikation “Why do tree-based models still outperform deep learning on tabular data?” gehen Grinsztajn et al. (2022) dieser Feststellung auf den Grund. Sie definieren einerseits einen Benchmark für tabellarische Daten, um eine Vergleichbarkeit unterschiedlicher Methoden zu ermöglichen und vergleichen verschiedene Deep-Learning- und Decision Tree Modelle auf tabellarischen Datensätzen. Andererseits untersuchen sie, aus welchen Gründen Decision Trees noch immer eine bessere Performance als Deep Learning-Verfahren auf Tabellendaten erreichen.
Was sind Decision Trees?
Bei Decision Trees handelt es sich um ein überwachtes maschinelles Lernverfahren, das für Klassifikations- (Ergebnis: Zuteilung zu einer von zwei oder mehr möglichen Klassen) und Regressionsaufgaben (Ergebnis: Zahlenwert) angewandt werden kann. Der Name des Verfahrens kommt von seiner hierarchischen Baumstruktur. Jeder Knotenpunkt entspricht einem Attribut und der Input wird je nach definierter Eigenschaft dem einen oder anderen Arm zugeteilt. Diese Struktur kann sich mehr und mehr verästeln, bis schliesslich bei der Überprüfung des letzten Attributs eine Klassenzugehörigkeit definiert, bzw. eine Zahl errechnet wird.
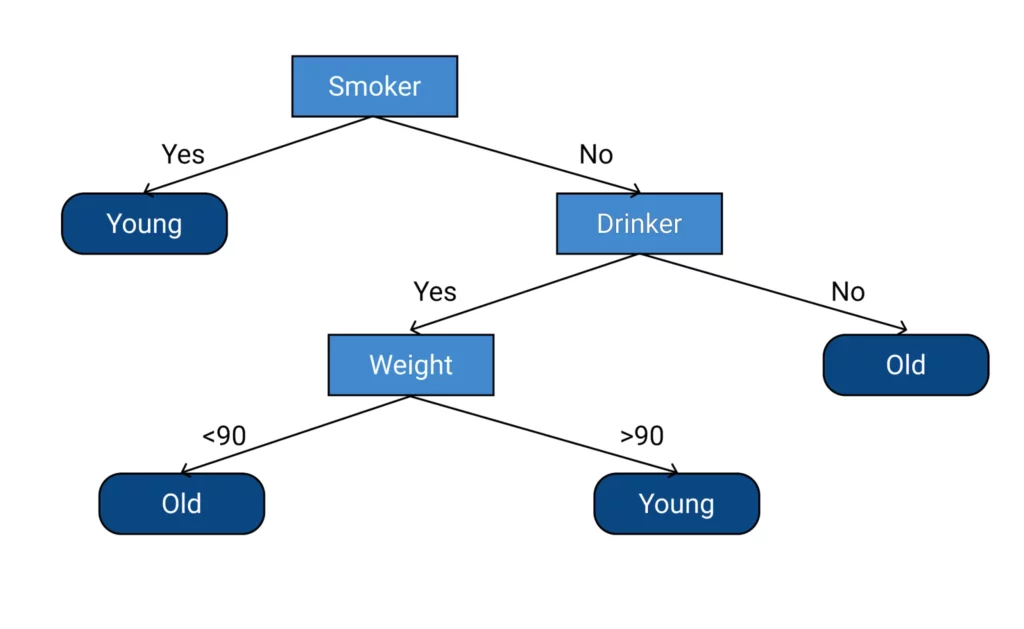
Trainiert wird ein entsprechendes Modell, indem die Trainingsdaten immer weiter nach Kriterien aufgeteilt werden, die die verschiedenen Klassen möglichst genau unterscheiden und somit die Wahrscheinlichkeit der Zugehörigkeit zu dieser erhöhen. Je feiner die Verästelung, desto genauer die Kriterien, aber auch desto komplexer das Modell. Zudem besteht die Gefahr, dass das Baummodell nicht mehr verallgemeinern kann und zu spezifische Merkmale der Trainingsdaten lernt (sogenanntes “Overfitting”).
Was ist Deep Learning?
Deep Learning ist eine Machine Learning-Methode, die auf einer Hierarchie von Konzepten basiert. Der Computer setzt komplexe Konzepte aus einfacheren zusammen und erhält so eine grosse Flexibilität und Leistungsfähigkeit für verschiedenste Aufgaben. Diese Konzepthierarchie geht Schicht für Schicht tief hinunter. Daher kommt der Begriff “Deep Learning” – tiefes Lernen. Insbesondere für Menschen intuitive, aber für den Computer schwierige Aufgaben, können so gelöst werden. Zum Beispiel Handschrifterkennung oder das Erkennen eines bestimmten Wortes in einer gesprochenen Sprachsequenz.

Machine Learning wiederum ist ein Gebiet der künstlichen Intelligenz, das Computern ermöglicht, aus Erfahrung zu lernen. Das Wissen muss so nicht explizit programmiert werden. Die künstliche Intelligenz ist ein Prinzip, das versucht, Computer in eine Denkrichtung zu bewegen, damit sie “intelligente” Schlussfolgerungen ziehen können.
Deep Learning basiert auf künstlichen neuronalen Netzen, deren Inspiration die Funktionsweise des menschlichen Gehirns ist. Das einfachste Deep-Learning-Modell ist ein neuronales Feedforward-Netz. Es besteht aus einer Eingabeschicht mit einer Anzahl Eingabeneuronen, in die die Daten eingegeben werden. Je nach Komplexität des Problems folgen darauf eine oder mehrere verdeckte Schichten, die die Information verarbeiten und an die nächste Schicht weitergeben. Die Ausgabeschicht gibt als Ergebnis eine Wahrscheinlichkeitsverteilung über verschiedene Klassen (im Falle einer Klassifikation) oder eine Zahl (im Falle einer Regression) aus.
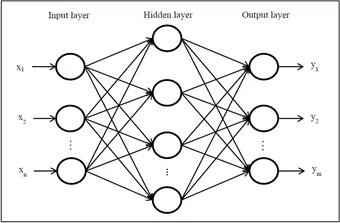
Ein Deep-Learning-Modell versucht, die Parameter in den verdeckten Schichten so zu optimieren, dass das Ergebnis möglichst präzise wird. Gleichzeitig muss es verallgemeinern können, um zuvor nicht gesehene Daten ebenfalls verarbeiten zu können (Vermeidung von sogenanntem “Overfitting”).
Ein Benchmark für bessere Vergleichbarkeit
Während in verschiedenen Bereichen Deep Learning Verfahren grosse Leistungsverbesserungen gegenüber herkömmlichen Methoden erzielen können, ist dies bei tabellarischen Daten noch unklar. Somit bleiben Entscheidungsbäume derzeit das Mittel der Wahl, wenn es um die automatische Verarbeitung von Tabellendaten geht.
Gleichzeitig sind tabellenspezifische Deep Learning-Architekturen ein sehr aktives Forschungsgebiet. Gemäss Grinszajn et al. (2022) wird in den meisten entsprechenden Publikationen behauptet, dass die entwickelten Deep Learning-Modelle Entscheidungsbaum-Architekturen übertreffen, oder zumindest mit ihnen mithalten würden. Diese Behauptungen würden jedoch auch oft in Frage gestellt. Da ein standardisierter Benchmark fehlt, sei eine direkte Vergleichbarkeit nicht gewährleistet und die Forschenden hätten relativ viel Freiheit bei der Evaluation einer Methode. Aus diesem Grund haben Grinszajn et al. (2022) einen Benchmark für tabellarische Daten entwickelt und eine präzise Methodik zum Einbezug von Datensätzen und der Feinstimmung mit Hyperparametern definiert.
Entscheidungsbäume erreichen bessere Ergebnisse für tabellarische Daten
Grinszajn et al. (2022) haben einen Standard aus 45 Datensätzen definiert, die klaren Kriterien entsprechen. Diese Datensätze stammen aus unterschiedlichen Bereichen. Ihnen gemeinsam sind die eindeutigen tabellarischen Datenmerkmale. Zusätzliche Herausforderungen, wie beispielsweise fehlende Werte, wurden entfernt, um sich auf die Kernaufgabe konzentrieren zu können. Auf diesen Datensätzen wurden in unterschiedlichen Settings Modelle basierend auf Entscheidungsbäumen und Deep Learning Verfahren miteinander verglichen. Die Ergebnisse zeigten, dass auf mittelgrossen Tabellendatensätzen Entscheidungsbäume nach wie vor State of the Art-Werte erreichen und Deep Learning Methoden neben der längeren Trainingsdauer eine niedrigere Performance erzielen.
Nach dieser Erkenntnis untersuchten die Autoren empirisch, woher diese Performance-Unterschiede bei tabellarischen Daten herrühren und kamen auf mehrere Erkenntnisse: Einerseits neigen neuronale Netzwerke zu übermässig geglätteten Ergebnissen und das Modell kann somit unregelmässige Muster in den Daten nicht lernen. Weiter beeinflussen informationslose Eigenschaften neuronale Netzwerke mehr als Entscheidungsbäume, die deren Relevanz definieren. Da tabellarische Daten viele informationslose Eigenschaften enthalten, führt dies zu gravierenden Einbussen in der Leistung eines Deep Learning-Modells. Weiter ist die Rotationsinvarianz (d.h. die Werte verändern sich bei einer Drehung nicht) von neuronalen Netzwerken nicht wünschenswert, da eine Veränderung der Ausrichtung von tabellarischen Daten ein Informationsverlust bedeutet.
Somit formulierten Grinszajn et al. (2022) drei Empfehlungen für Personen ab, die Neuronale Netzwerke für tabellarische Daten entwickeln:
- Das Modell muss robust gegenüber informationslosen Eigenschaften sein
- Die Orientierung der Daten muss im Modell zwingend beibehalten werden
- Das Modell muss in der Lage sein, leicht irreguläre Funktionen zu erlernen
Fazit
Die Publikation von Grinsztajn et al. (2022) zeigt, dass Deep Learning-Verfahren zwar in vielen Gebieten grosse Fortschritte im Bereich des maschinellen Lernens erreichen konnten, für gewisse Arten von Daten und je nach Anwendung, herkömmliche Machine Learning-Verfahren aber nach wie vor besser geeignet sind. Dies ist beispielsweise bei tabellarischen Daten der Fall.
Quelle: Grinsztajn, L., Oyallon, E., & Varoquaux, G. (2022). Why do tree-based models still outperform deep learning on tabular data? https://doi.org/10.48550/ARXIV.2207.08815